Google-Dremel论文摘要与笔记
本文阐述对Dremel: Interactive Analysis of Web-Scale Datasets论文内容的理解。有助于理解Parquet数据格式。
0. 目录
1.嵌套数据模型
1.1.文字描述
1.2.树描述
1.3.路径
2.列存储
2.1.repetition level
2.2.definition level
3.读取记录
3.1.有限状态机
3.2.查询
1. 嵌套数据模型
嵌套数据模型可以用文字和树的方式描述,但记录的实例只能用文字描述,因为树模型无法表示出多值字段的某个取值的位置。下面通过一个例子来进行说明。
1.1. 文字描述
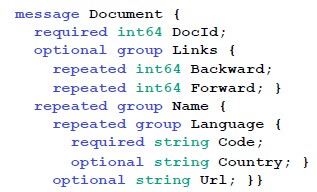
上图中的相关术语说明:
- field:在论文中,它可以表示组字段(比如Name),也可以表示基本类型字段(如Code)
- repeated:该字段在它的上一级嵌套中可能出现一次或多次。可以不出现。该字段在一条记录中的多个值被描述为一个值列表。该值列表中值的顺序是有意义的,它关系到如何解释该值在嵌套结构中的位置。
- required:该字段在它的上一级嵌套中只会出现且必须出现一次。
- optional:该字段在它的上一级嵌套中不出现或只会出现一次。
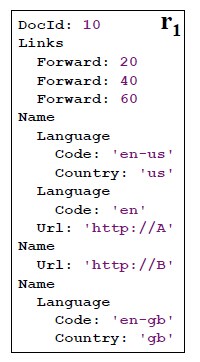

1.2. 树描述
树的每一个叶子都是一个基本类型。
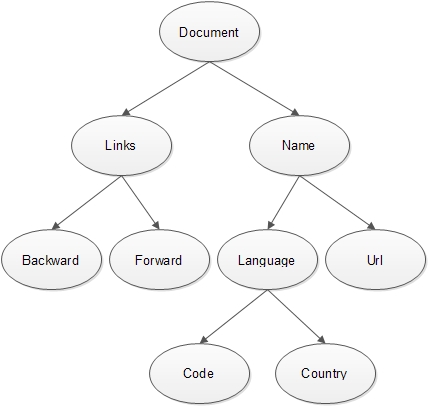
1.3. 路径
每一个基本类型字段都拥有一个路径,作为该字段的标识符。上述模型各个基本类型字段的路径如下:
DocId
Links.Backward
Links.Forward
Name.Language.Code
Name.Language.Country
Name.Url
2. 列存储
为了使得存储的数据量达到最小,只存储基本类型字段的值。使用列式存储可以方便对数据的压缩,因为同一列的值都有相同的类型。也就是说,上述模型的记录将按照如下格式进行存储。
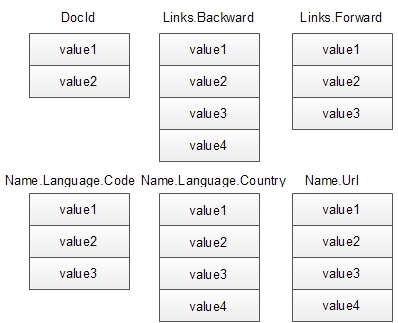
但是,从以上存储可以看出,对于某一个值,我们无法确定它在原记录中的位置信息。因此,论文中引进了以下两个概念来描述位置信息。
2.1. repetition level
概念
描述在一条记录中,当前值所属字段是在其字段路径中的哪一个repeated字段层面重复了,若该字段在一条记录中是第一次出现,则repetition level=0。
说明
在嵌套数据模型中,每一个嵌套结构都可能在其上一级嵌套中重复出现,因此每一个基本类型字段在记录中重复出现的原因有:
- 它自己是可重复的
- 随着它所属的嵌套结构重复出现
如果把它自己也算作一种嵌套结构,那么该字段所属的嵌套结构就是一层或多层的,所以repetition level就是用来确定:一个字段的某次重复出现,相对于上一次出现,是由第几层嵌套结构引起的。所谓重复出现,是指字段重复出现,而不是字段的值重复出现。
例子
比如记录r1中,基本类型字段Name.Language.Code,它所属的嵌套结构有三层,第一层是Name结构,第二层是Language结构,第三层是Code结构。其中,Name和Language是repeated类型的,也就是可重复的,将这些可重复的嵌套结构进行标记,Name标记为1,表示第1层会引起字段重复的嵌套结构,Language标记为2,表示第2层会引起字段重复的嵌套结构。Name.Language.Code在该记录中总共出现了三次,分别对应三个值’en-us’、’en’、’en-gb’。在该字段第一次出现时,其值为’en-us’,因为在这条记录中它不是重复出现的,其repetition level=0。在该字段第二次出现时,其值为’en’,字段已经重复出现了,这时需要判断的是:相对于上一次出现,这一次出现是由第几层可重复嵌套结构引起的。从图中可以看到,它是由Language引起,因此repetition level=2,表示是由第2层可重复嵌套结构引起的重复。同理,在该字段第三次出现时,从图中可以看到,是由Name引起的重复,因此repetition level=1。
缺陷
当有些结构缺失的时候,只根据repetition level无法明确描述字段在记录中的位置。比如在记录r1中,若只有repetition level的话,Name.Language.Code列可以存储为:
| Name.Language.Code | |
|---|---|
| value | repetition level |
| ‘en-us’ | 0 |
| ‘en’ | 2 |
| ‘en-gb’ | 1 |
假设其他字段都能正确描述记录,那么根据上述存储恢复出来的记录是:
DocId: 10
Links
Forward: 20
Forward: 40
Forward: 60
Name
Language
Code: 'en-us'
Country: 'us'
Language
Code: 'en'
Url: 'http://A'
Name
Language
Code: 'en-gb'
Url: 'http://B'
Name
Language
Country: 'gb'
可以看到,第三个Code被错误地放到了第二个Name里面,这是第二个Name里面Code的缺失导致的。在第二个Code之后,Name重复出现了两次,而第三个Code的repetition level只描述了一次Name的重复,因此它无法说明自己所属的Name是第二个Name还是第三个Name。
为了更明确地描述记录,需要引进其他信息。这个信息被称为definition level。
2.2. definition level
概念
描述在该字段路径中,有多少个可缺失的字段(即非required类型的字段)是实际存在的。
说明
为了弥补repetition level的缺陷,可以采取的方案是对于每一条记录,将数据模型中定义了的所有字段都附上值,若该字段在记录中没有出现,就给它补上null值使其出现,然后再进行repetition level的计算。如记录r1在填充了null值之后就会变为:
DocId: 10
Links
Backward: null
Forward: 20
Forward: 40
Forward: 60
Name
Language
Code: 'en-us'
Country: 'us'
Language
Code: 'en'
Country: null
Url: 'http://A'
Name
Language
Code: null
Country: null
Url: 'http://B'
Name
Language
Code: 'en-gb'
Country: 'gb'
再以Name.Language.Code列为例,它的存储变为:
| Name.Language.Code | |
|---|---|
| value | repetition level |
| ‘en-us’ | 0 |
| ‘en’ | 2 |
| null | 1 |
| ‘en-gb’ | 1 |
但是,这样仍不能完全描述记录。比如,当要从记录r1中只恢复部分字段,如只恢复Code字段时,正确的、包含完整嵌套结构(即对于不想恢复的字段,只不显示基本类型字段,保留其嵌套结构)的恢复记录应该是:
Name
Language
Code: 'en-us'
Language
Code: 'en'
Name
Name
Language
Code: 'en-gb'
其中,null值的Code不显示,与原始记录一样。
可是,由存储恢复出来的记录是:
Name
Language
Code: 'en-us'
Language
Code: 'en'
Name
Language
Name
Language
Code: 'en-gb'
可见,在第二个Name中多出了并不存在的Language字段。这是因为在恢复null值字段的时候,只根据repetition level无法确定这个null值是由哪一个嵌套结构的缺失引起的,所以恢复时只有两种选择:一是将所有嵌套结构全都恢复,二是全都不恢复。上述例子就是全都恢复的情况。无论哪一种,都可能造成恢复记录与原本记录的嵌套结构不符。
因此,definition level就是用来描述null值是由哪一个嵌套结构的缺失引起的,使得恢复记录时可以正确地恢复嵌套结构。
例子
仍以记录r1中的Name.Language.Code为例。在填充上null值之后,Name.Language.Code在该记录中总共出现了四次,分别对应四个值’en-us’、’en’、’null’、’en-gb’。根据definition level的定义,总的可缺失字段数目为2,当它们实际都存在时,definition level有最大值为2。实际上,它也是所有非null值Code字段的definition level。因此,第一、二、四个Code字段的definition level都为2。对于第三个Code字段,其路径中的Name是存在的,Language是缺失的,路径中实际存在的可缺失字段总数为1,根据定义,definition level=1。因此,记录r1中Name.Language.Code列的存储为:
| Name.Language.Code | ||
|---|---|---|
| value | repetition level | definition level |
| ‘en-us’ | 0 | 2 |
| ‘en’ | 2 | 2 |
| null | 1 | 1 |
| ‘en-gb’ | 1 | 2 |
这里解释一下definition level为什么描述了null值是由哪一层嵌套结构的缺失引起的。在该字段的路径中,Name和Language都是可缺失的嵌套结构,那么,总共有2层会引起null值的嵌套结构,它等于definition level的最大值。如果definition level=1,因为Name缺失必然引起Language缺失,说明Name存在,Language缺失,即引起null值的就是Language嵌套结构。如果definition level=0,说明Name缺失,即引起null值的就是Name嵌套结构。
3. 读取记录
如何将按需将多个列恢复成记录呢?论文中采用的方法是创建一个有限状态机。
3.1. 有限状态机
概念
有限状态机的生成参数是由需要提取的列构成的模式。生成的状态机的状态即为要提起的列,转移条件为当前读取值的下一个值的repetition level。
例子
比如要提取DocId和Name.Language.Country。那么它所构成的模式就是:
message Document {
required int64 DocId;
repeated group Name {
repeated group Language {
required string Code; }}}
由该模式作为参数传进生成状态机的过程中,然后该过程就会自动生成一个可读取该模式记录的有限状态机,先不关注生成过程的算法描述,因为其生成逻辑是可以从模式直观推理出来的。状态机的状态即为需要提取的列DocId和Name.Language.Country,如下图所示。
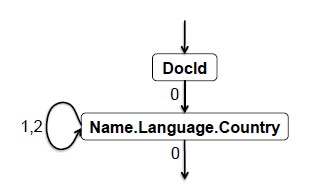
说明:在这里,为了使叙述更清楚,将列存储中的每一行称为一个字段。从图中可以看出,状态机的初始状态是DocId,当前的读取数据的指针指向DocId列的第一个字段,从该列取出definition level,判断该字段的值是否为null(definition level不为最大值则为null),若不为null则将值读取出来,然后追加到输出的记录中,若为null则由definition level判断是第几层嵌套结构缺失,然后追加还存在的那些嵌套结构到输出记录中。对当前字段做完处理后,取出下一个字段的repetition level,由于DocId是required类型,即在当前嵌套结构中只会出现一次,所以无论repetition level的值是多少,读取数据的指针都必然会跳转到Name.Language.Country列。又由于DocId不会出现重复字段,所以repetition level的值只可能为0。那么,读取数据的指针现在指向了Name.Language.Country列的第一个字段,它与DocId列的第一个字段同属一条记录。对当前字段做完操作后,取出下一个字段的repetition level,由于Name.Language.Country路径中的Name、Language嵌套结构都是可重复的,因此当repetition level=1或2时都说明下一个字段仍属于同一条记录,因此指针指向下一字段并做取值操作。直到repetition level=0,说明下一个字段已经属于下一条记录,这时一条记录的读取已经完毕,跳出状态机。
3.2. 查询
查询过程的输入有两个,一个是读取字段Reader的集合,另一个是标量表达式的集合。Reader集合中每个Reader对应查询语句中出现的每个基本类型字段。标量表达式包括查询中出现的表达式,包括聚集函数。查询的执行过程是这样一个循环:从Reader中读取字段->where语句判断->select语句选出需要的值->组织成记录->下一条记录。